
The past few years have been rough for chipmaker AMD. Ever since Intel launched the Core 2 series, they’ve been playing a constant game of catch-up as far as CPU performance goes. In 2006, they purchased GPU maker ATI, and spun-off their fabrication plants to create a new entity, GlobalFoundries. AMD had lofty goals to merge the CPU and the GPU, the Fusion initiative, as well as revolutionize the industry with an entirely new microarchitecture, called Bulldozer.
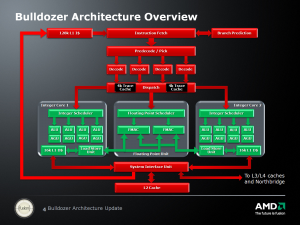
Originally slated for a 45nm process, that version of Bulldozer was canceled and delayed for 32nm. AMD had talked up its clustered multithreading (CMT), which allows for more concurrent operations without increasing die size by adding more cores, sharing building blocks such as cache, the fetch unit, decode unit, and a double-wide floating point unit (FPU). In Bulldozer, each module contains a shared fetch, decode, cache, and a floating point unit. In theory, this allows up to an 80% increase in multithreaded performance with minimal die area increases.
In practice, the launch of Bulldozer was a disaster for AMD. Because of its long pipeline, it required higher clock speeds to reach the same level of performance as their previous K10 architecture found in Phenom II. The CMT architecture also gave each individual process fewer resources than traditional architectures, cache had higher latency, and the wide FPU could only execute two threads using newer software extensions most software simply didn't use. AMD also had the unfortunate problem of the Phenom II X6 being an affordable hex-core on a proven process, so it was used as a point of comparison more often than the Phenom II X4. Windows 7 also had issues with scheduling threads on a per-module basis, preventing the Turbo feature from kicking in.
Launching a new architecture on a new process leaves two levels of uncertainty, which is why Intel sticks to its famous tick-tock cycle, in which the previous architecture is adapted to a new process, and then a new architecture introduced after the process has matured. However, as they had spun off their fabrication plants, AMD was at the mercy of whatever process GlobalFoundries could put out. The result was a hot chip that did not live up to expectations. AMD didn’t even bother to put it in mobile chips; they stuck with their old Phenom II in the form of Llano.
(AMD’s Plans)
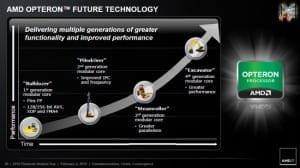
AMD noted that Bulldozer was the first of at least four planned generations of this architecture. In 2012, they launched Piledriver, which was largely Bulldozer with cache enhancements, bug fixes, and a more mature process, capable of sustaining higher clocks while using the same amount of power. Piledriver did make it into mobile, in the form of Trinity and Richland, both of which were Piledriver modules paired with AMD’s VLIW4 GPU architecture, found on Radeon 6000 series cards.
However, AMD’s exclusivity agreement with GlobalFoundries meant that Piledriver was still on a 32nm process, even as Intel hit 22nm and TSMC hit 28nm. GlobalFoundries has recently been able to get its 28nm process going, and Kaveri, a chip with two Steamroller modules paired with AMD’s latest Graphics Core Next (GCN) architecture on a single die.
(What’s changed)
While Piledriver was largely a refinement of Bulldozer, it was referred to as a second-generation version, and carried the internal name of bdvr2. However, it did not introduce any large architectural changes, and given the new process, I would say that Steamroller is more accurately referred to as the second generation of Bulldozer, with Excavator being a future, further refinement. The biggest change that AMD made was dropping the shared decoder, which gives each thread its own discrete decode unit, which was a key bottleneck in single-threaded performance on Bulldozer and Piledriver.
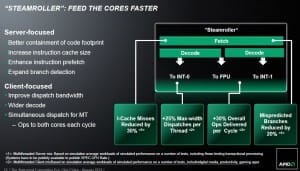
However, by virtue of being on a 28nm process rather than a 22nm process, AMD only gets the density advantage of a half-node, not a full node. The chip landscape has also changed since AMD started design…many foundries are optimizing their processes for low-voltage, low-leakage mobile use, with the focus on low power performance per watt. The entire Bulldozer family was designed in an era when AMD expected the trends of high-wattage processes with performance as the main goal, with performance per watt at higher wattages, to still be the norm.
(Test Setup and Methodology)
I ran a series of tests on chips from all three architectures to see how they stack up. AMD was gracious in sending us an FM2+ motherboard and an A10-6790K, a Richland chip. I had an FX-8150 and FX-8350 on hand as well. For these tests, I ran them in both Windows and Linux, specifically Fedora 20 x86_64. I like to use Linux because it’s much faster than Windows to support patches for architectural changes, a lot of software is faster to support new instruction sets, and open-source code means that software can easily be changed and audited.
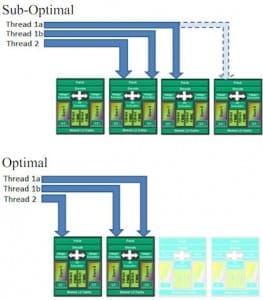
For instance, as previously noted, Windows 7 had an issue with scheduling threads on a per-module basis, which prevented Turbo modes from activating. Microsoft worked with AMD to get two patches out, but they were largely band-aids. It was not until Windows 8 that Microsoft was able to get the thread scheduler to work well. Because software isn’t static; what you run now will be different in a year, and even in six months. Linux allows us to test a few more bleeding-edge features.
As AMD sent us an A10-6790K, I performed a slight overclock to match the stock speeds of an A10-6800K. Default clockspeeds are the only difference between these two chips, so I have labeled them as an A10-6800K in these tests. I used that chip in addition to an A10-7850K, an FX-8150, and an FX-8350. As the FX-series have more modules, I also ran the tests with two of the modules disabled on those chips, to give a more accurate comparison between all architectures. With the same clockspeeds and number of cores, the only large difference that remains is that the FX chips have L3 cache, something AMD does not include on its APU’s for the time being.
I used 2133MHz memory for all tests since the integrated GPU within the APU’s requires higher speed memory for maximum performance. As the FX series lacks integrated GPU’s, I used a Radeon 7970 GHz Edition for the run, but it would not have an effect on pure CPU benchmarks. All runs were also run on an Intel X25-M SSD to avoid any disk-based bottlenecks.
Test Type I: Cryptography and Compression
Cryptography is something we all rely on. The internet wouldn’t feasibly exist without it. Using the Phoronix Test Suite in Linux, we can run a variety of algorithms to see how they stack up. Cryptography is particularly interesting on AMD systems because there are many use cases where AMD supports encryption instruction sets on many chips that Intel reserves for Xeons.
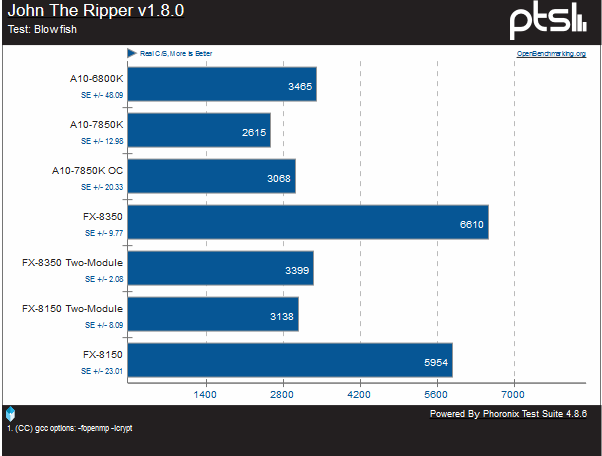
Our first test is the Blowfish algorithm. This algorithm has been around since 1993, and while not as widely used, it is still considered a reliable algorithm and no effective attacks against if have been found in the past two decades. Here we see a clear regression from Piledriver to Steamroller, and even at matching clocks, a bit of a regression from Bulldozer. When going from Bulldozer to Piledriver, we saw a reasonably large increase, noting that the FX-8150 outputs 5954 C/S and the FX-8350 outputs 6610 C/S. Even with clockspeeds and modules normalized, even the original FX-8150 at 3138 outclasses the A10-7580’s 3068.
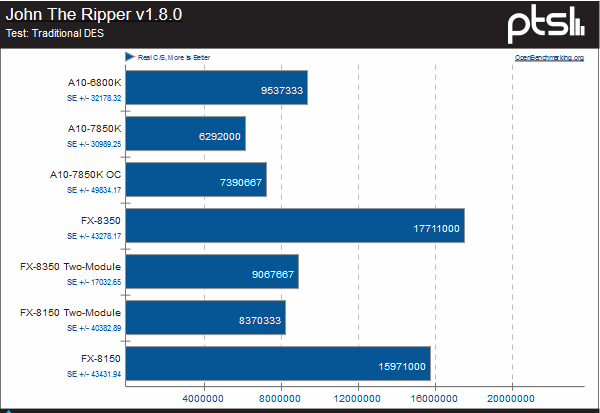
DES is a bit of an older algorithm, designed by IBM in the 1970’s. DES is no longer considered a secure algorithm because of its short key length, and suspicions that the National Security Agency (NSA) intentionally sabotaged it in the 1980’s. The Electronic Frontier Foundation once proved that it could be brute-forced in less than 24 hours. Despite these issues, it was used by some software until the 1990’s, so it’s a useful point of data, even if newer software won’t be using it. Again we see a regression from Piledriver and even Bulldozer. The deltas between Steamroller and Piledriver are even more apparent in this algorithm, although I can’t imagine AMD put too much effort into running a depreciated algorithm effectively.
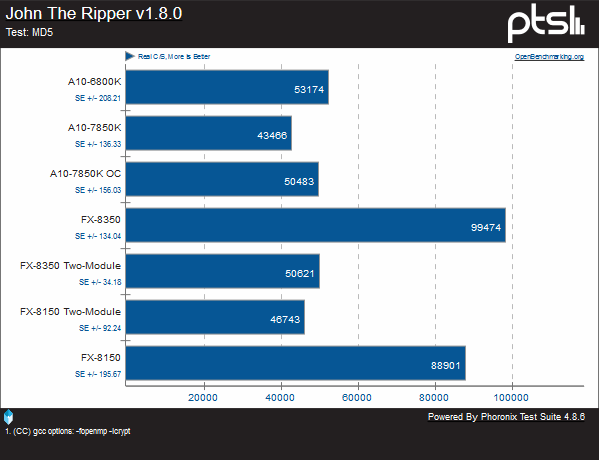
MD5 is an algorithm most commonly used for hashing, to verify the integrity of data received. While largely deprecated by SHA-1 and SHA-2, it is very common to see free software packages still listing the MD5 hash of a package. Here we see a clear lead over Bulldozer clock for clock, while having a small regression from Piledriver. The FX-series chips will all modules enabled continue to dominate the tests.
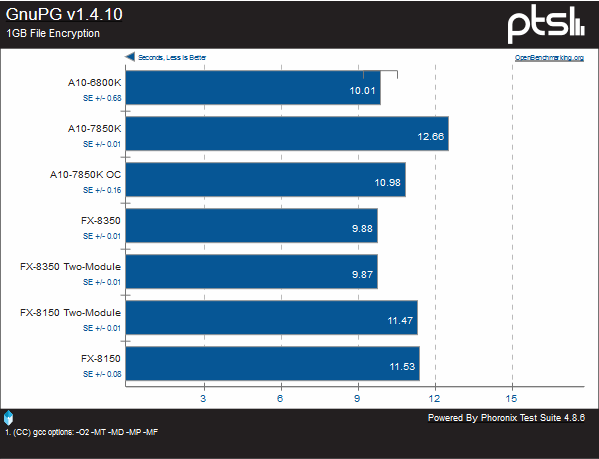
This test sees how long it takes to encrypt a 1GB file using the GNUPG suite, an alternative to PGP. Another regression is seen here, albeit only by about a second clock-for-clock. We do see a consistent lead over Bulldozer, and we can see that the L3 cache is not a factor here.
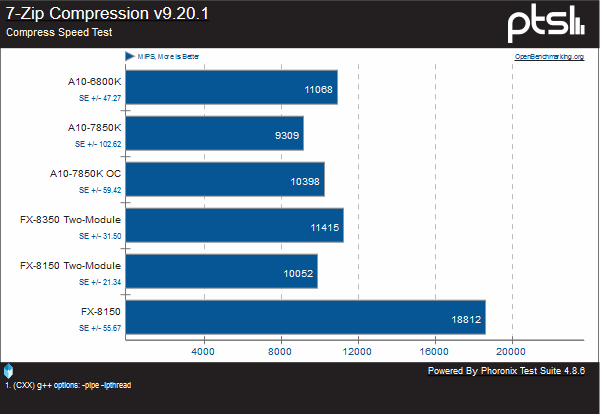
I was unfortunately unable to get a few of the compression and decompression tests to properly run on a stock FX-8350, despite multiple installations of both the packages and the operating system. However, it was able to run on every other configuration. Despite the FX-8350’s absence, we largely see a repeat of the cryptography tests in this case; a regression from Piledriver at the same clocks. In this case, an A10-7580K is nearly 10% behind an A10-6800K.
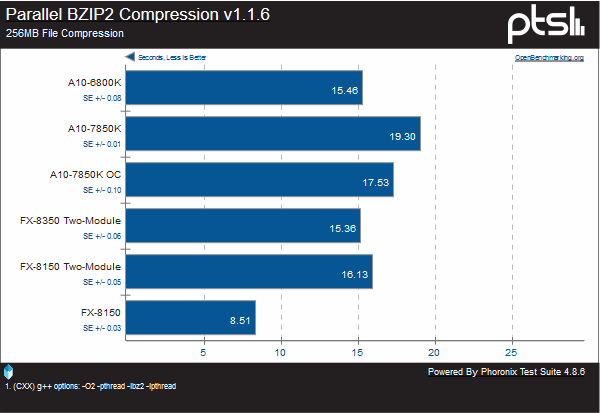
We see more regressions here, though it is notable that because the FX-8350 Two-Module ant A10-6800K are very close, L3 cache is not a factor in this test. The FX-8150 is a clear leader here, having twice the threads to work with.
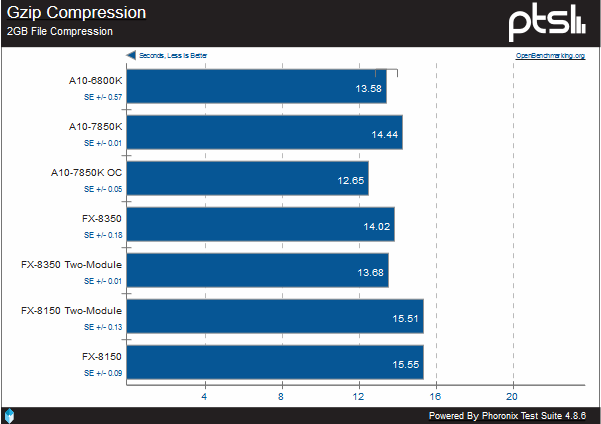
With this algorithm, we see a reversal; Steamroller wins against both Bulldozer and Piledriver at the same clocks. As seen by the margin-of-error delta between the FX-8150 with two and four modules, this is a test that is reliant on single-threaded performance.
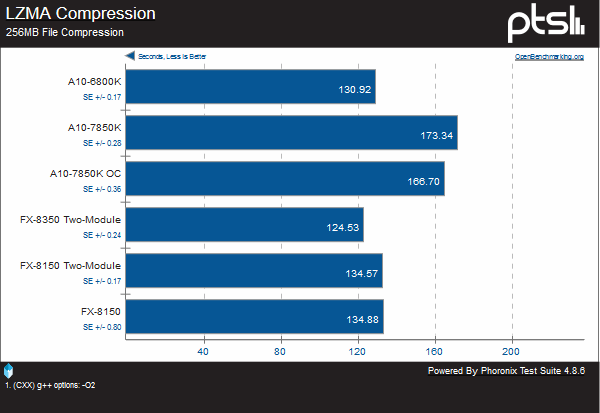
However, it goes back to what we’ve been seeing with other tests on this one: a regression. In this case, we see a very large regression. Steamroller takes nearly forty seconds more than an equivalent Piledriver chip.
Test Type II: Multimedia
While AMD has nothing on their roadmaps that shows them competing with Intel for high-end CPU performance, they aren’t cutting out performance entirely. They’re promoting initiatives like Heterogeneous Computing (HUMA), which leverages the relative strengths of a CPU, a GPU, or both in areas that it makes sense. Photo editing, video transcoding and other multimedia tasks are excellent candidates for HUMA.
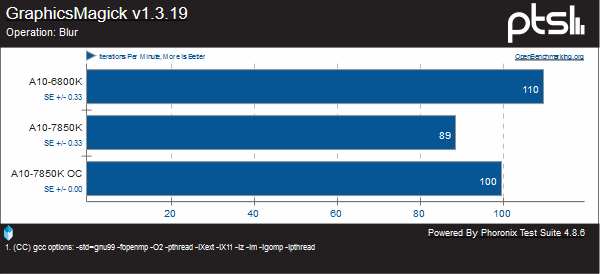
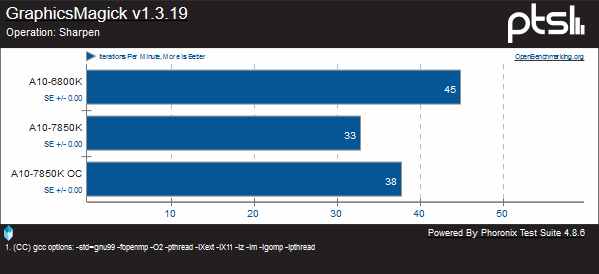
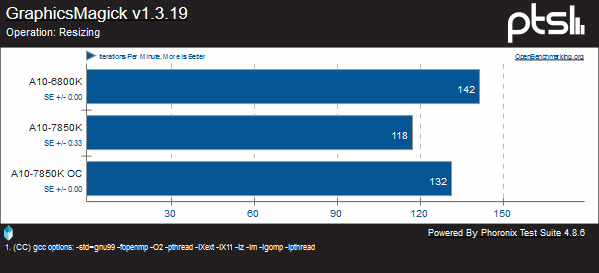
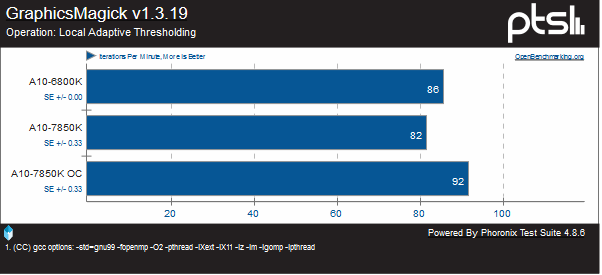
Unfortunately, I was unable to get GraphicsMagick to run properly on my FX chips. But we can measure Kaveri against the Richland chip it replaces. Here we can see that Steamroller is again a regression clock for clock on the chip it replaces, with the exception of the Local Adaptive Thresholding test, where it is capable of six more iterations per minute.
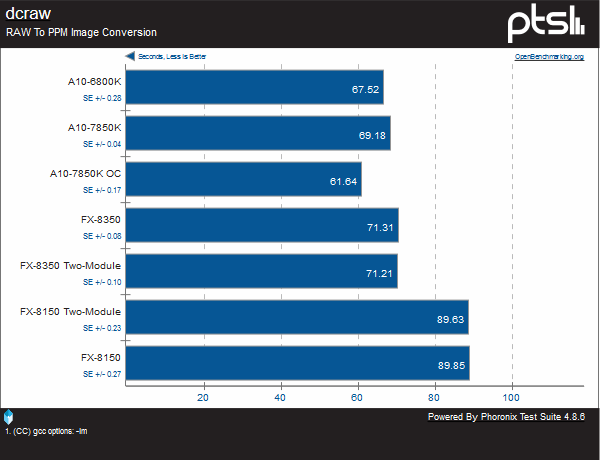
In this test, RAW images are converted to PPM. Clock for clock, the Steamroller-based Kaveri is the winner, with the Piledriver-based Richland coming in a close second.
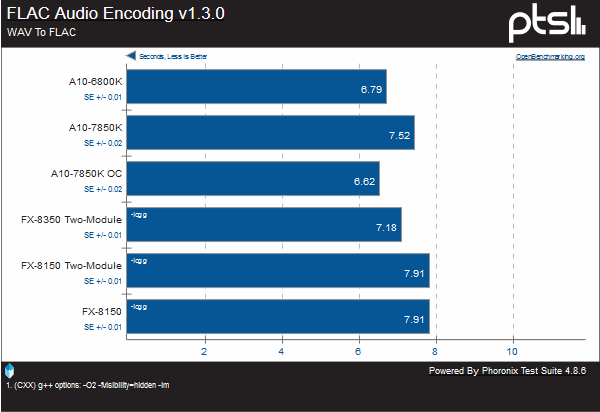
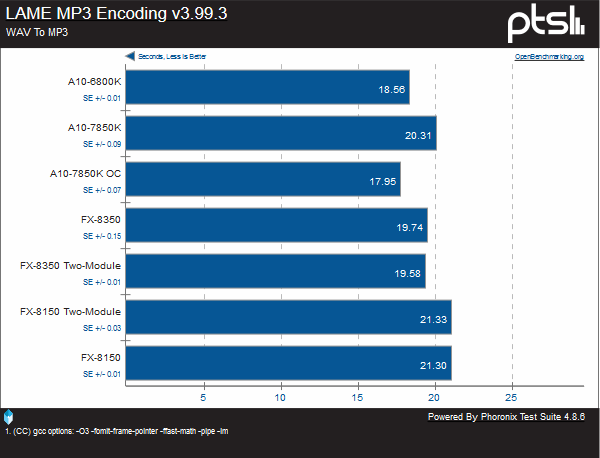
In these audio encoding tests, Kaveri does fare better than any other chip, however both Piledriver chips are only two seconds behind.
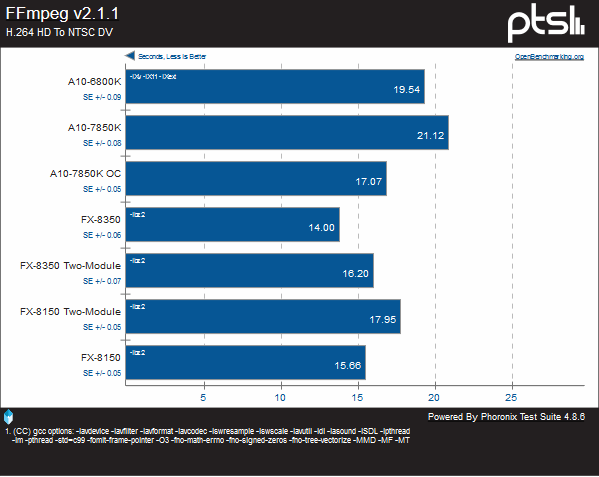
In this conversion test, we see Kaveri best Richland, but Vishera is faster overall. This test likely benefits from a bit of L3 cache, which the APU’s lack. Notable that despite having half the modules, at stock Kaveri is only 33% slower than Vishera.
Test Type III: Compilation, Scientific, and Misc:
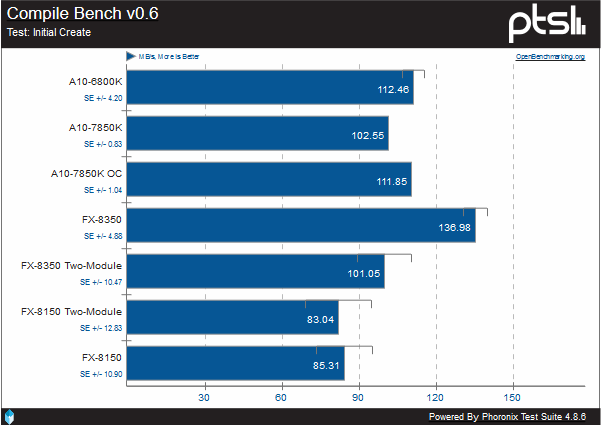
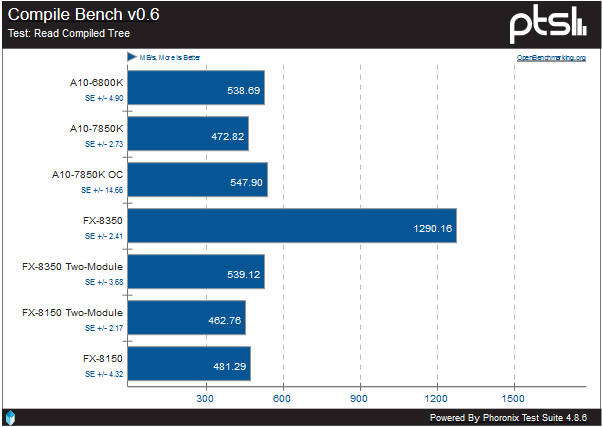
In this test, we see that while not having much of a lead over Piledriver, it is a lead, and a clear one over the original Bulldozer. The FX-8350 still has a commanding lead, however.
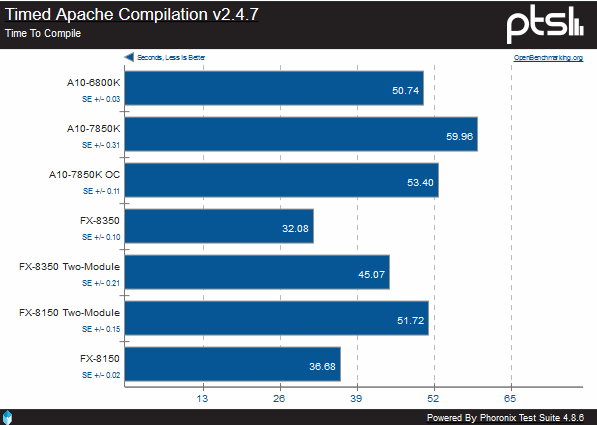
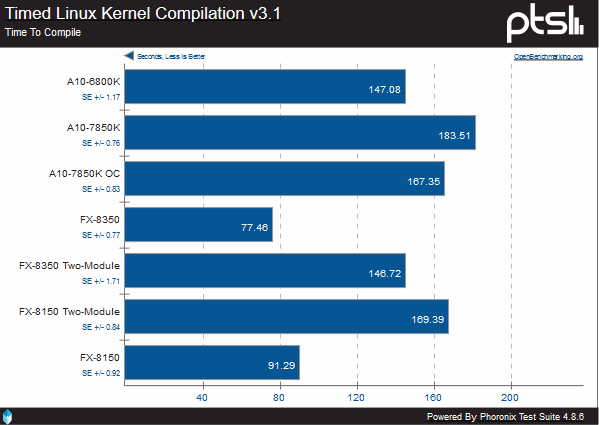
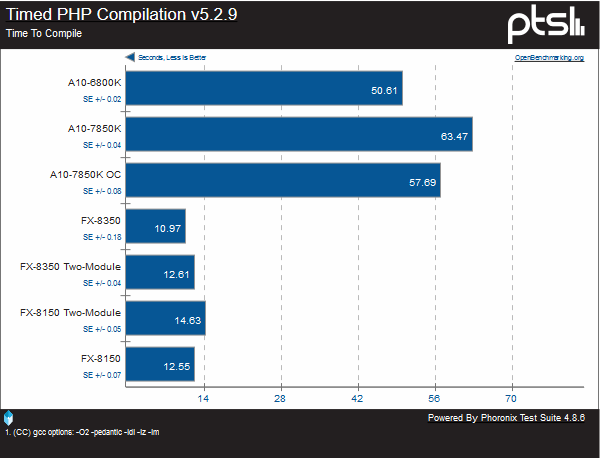
Here we compile three specific pieces of software: Apache, PHP, and the Linux kernel. In all cases, the FX-8350 is the clear winner, with Steamroller falling behind even the original Bulldozer with the same number of modules.
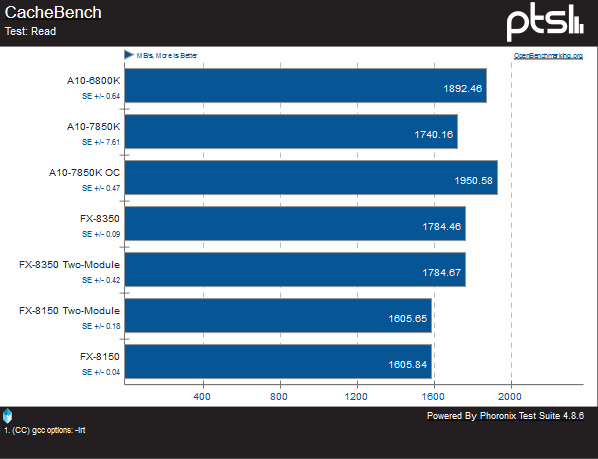
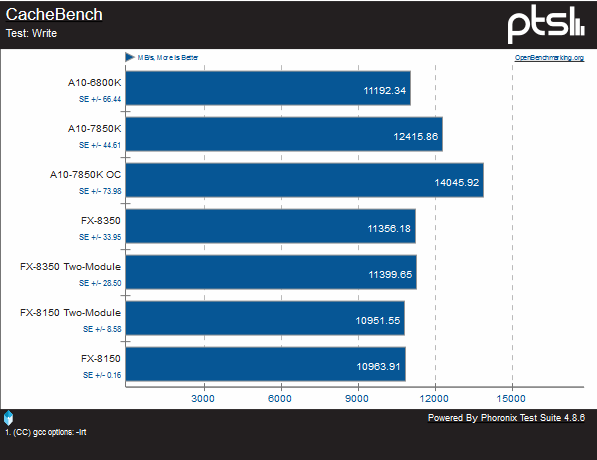
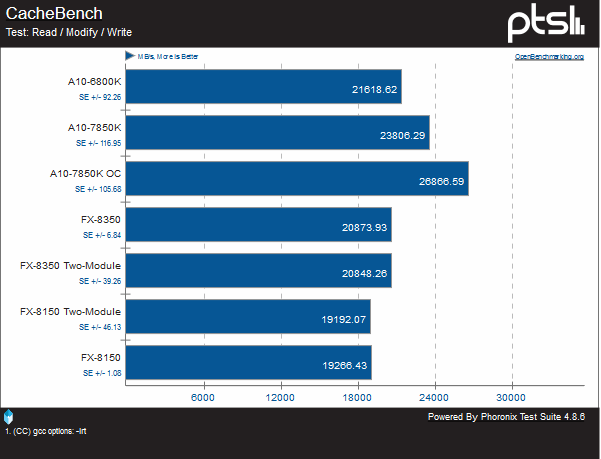
AMD seems to have improved Steamroller’s cache considerably. In pure read and write tests, there is a respectable gain, but when real-world use of constant read/modify/write is done at once, it is nearly 20% faster than even the FX-8350.
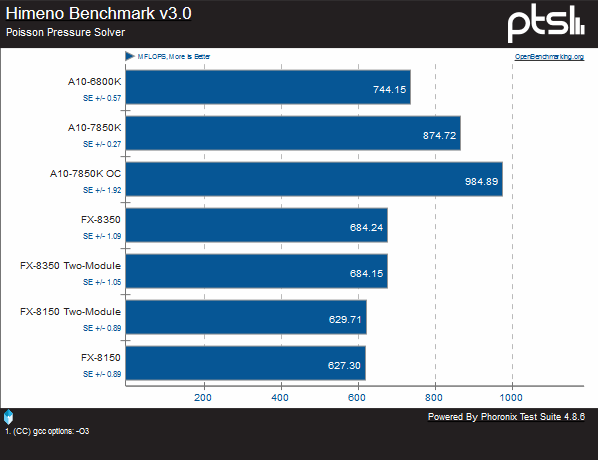
Himeno is a scientific test used to calculate operations used in discrete mathematics. Herte we see Steamroller take a very large lead over the FX-8350
Test type IV: Synthetics
AMD was very kind and provided us with copies of PCMark8 and 3DMark. A nice thing about PCMark in particular is that you can run the same suite of tasks on the CPU only or with the GPU assisting it. AMD is pushing a unification of CPU and GPU with Kaveri, saying that the future lies with a strong GPU and unified memory. While previous APU’s such as Llano, Trinity, Zacate, and Kabini have had a CPU and GPU on one die, they lacked the memory access that Kaveri now has. For these tests, I can everything at stock speeds, sans the 6790K that I have set to match a 6800K.
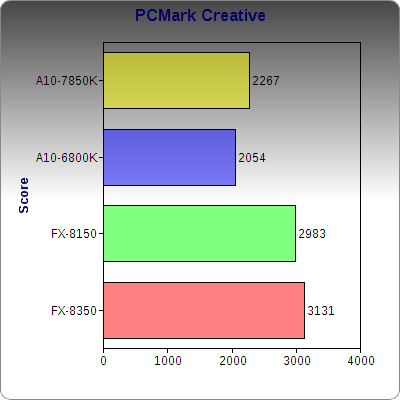
In a suite of tasks that involves various photo resizing, cropping, recoloring, video transcoding, video chats, and gaming, Kaveri is a small step above Richland, but does so with lower clocks and a lower TDP. The FX chips, having twice the modules and L3 cache, are faster than the APU’s, but by a smaller margin that one might imagine.
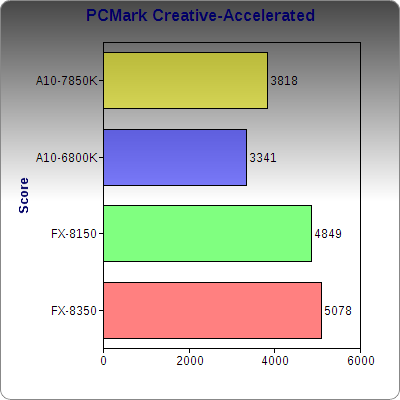
Add a GPU into the mix, and we see that even Richland exceeds the capabilities of a CPU-only FX-8350. Interestingly, there’s only about a 25% gain in going to a full-blown Radeon 7970 for this test. While Kaveri may lose in absolute speed, it absolutely wins in performance per watt.
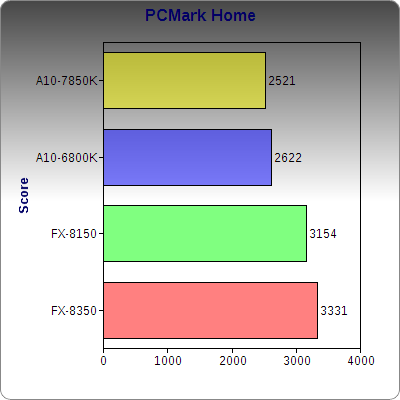
PCMark’s Home suite combines a mix of web browser performance, light gaming, photo editing, and Office application. Sadly, we see another small regression from Richland in this instance, but not by a large amount.
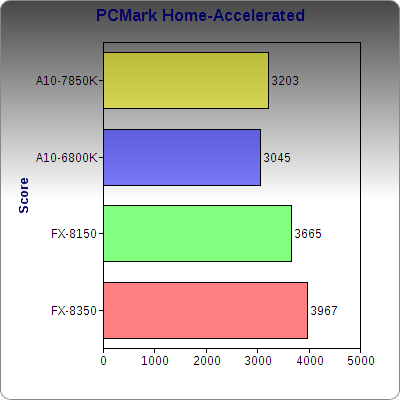
However, with the GPU in place, we see a repeat of the previous test with OpenCL: It outperforms Richland, and the FX/7970 combination sees a less than 20% gain over Kaveri, leading to a greater performance per watt.
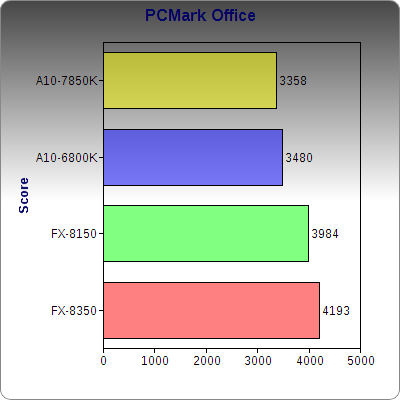
PCMark’s Office test goes through various tasks with Microsoft Office, measuring how quickly and effectively it can open, edit, and create files. As we can see here, Kaveri does outperform Richland and fall behind FX, but all four chips are reasonably close to each other, within 500 points. If Office work is a priority, all of these chips fit the bill. At this time, there is no OpenCL support in this suite.
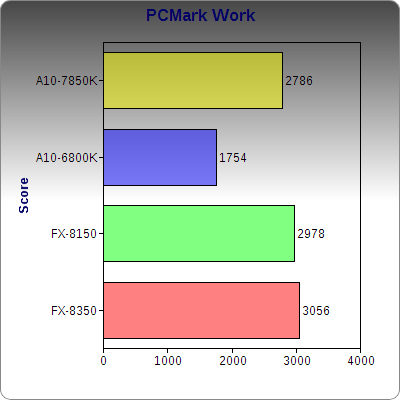
PCMark’s Work Suite tests web browsing, video chat, writing, and spreadsheets, but not in Microsoft Office. Kaveri comes very close to the original FX-8150, but the FX-8350 is faster still.
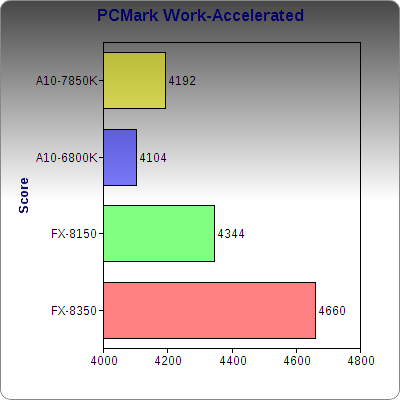
The results mirror the other OpenCL tests: the FX-8350 with a Radeon 7970 reigns supreme in raw performance, but Kaveri is less than 20% behind while using substantially less power.
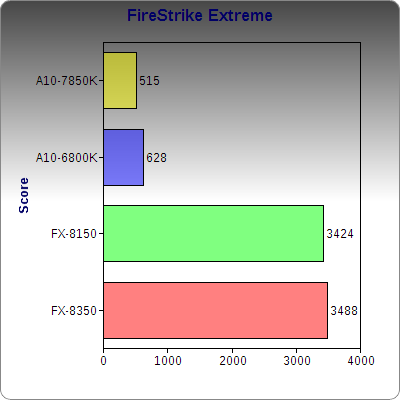
Firestrike Extreme is a demo in 3DMark that uses cutting-edge graphics techniques and dense imagery to stress and test a video card. While the CPU does play a small role, the primary part being tested is the GPU. For how well it did in OpenCL tasks, Kaveri’s GPU falls far behind the Radeon 7970, which has its own GDDR5 memory as opposed to shared DDR3.
Test Type V: Gaming
Since AMD acquired ATI in 2006 and released Llano in 2011, they’ve touted their APU’s as being good for video games. While Intel’s Iris Pro does outperform Kaveri’s GPU at low resolutions, Intel only has it on very expensive chips, and it begins to choke the higher the resolution goes.
While most PC gamers would laugh at the idea of using integrated graphics over a discrete card, there’s a good segment of the population that would benefit from Kaveri’s improved GPU without having to spend extra money on a discrete GPU, as well as the benefit that it gives to laptops. Kaveri runs the same type of GPU as found in the Xbox One and PlayStation 4, and those two devices having eight Jaguar cores will force developers to more effectively multithread their games, giving AMD’s individually weaker per-thread performance a boost. AMD is also touting Mantle, a new API that allows for much closer to the metal programing than what DirectX would allow. I tested games at 1440x900 and 1920x1080, two of the most common screen resolutions on desktops, and the former is increasingly common on laptops.
Batman: Arkham City
I chose Arkham City over Arkham Origins because frankly, while being newer, Origins is a buggy mess with issues that have been around since launch that haven’t been patched, with the developer saying they’re putting their focus on DLC. Arkham City, on the other hand, is a very stable game with minimal bugs.
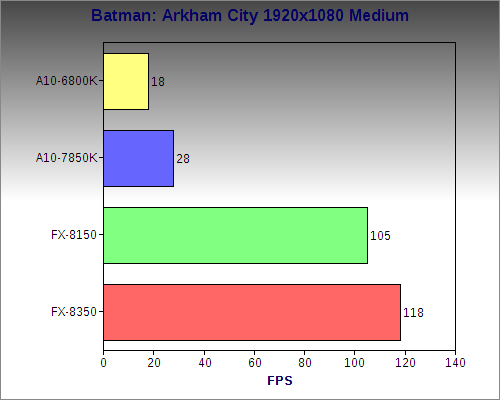
Arkham City was passable for Kaveri, but it's no match for a higher end discrete card like the 7970 paired with an FX-8350. If details were toned down a bit, the FPS could be bumped higher, but these are the default medium settings. it would also be faster at 1440x900.
Bioshock Infinite
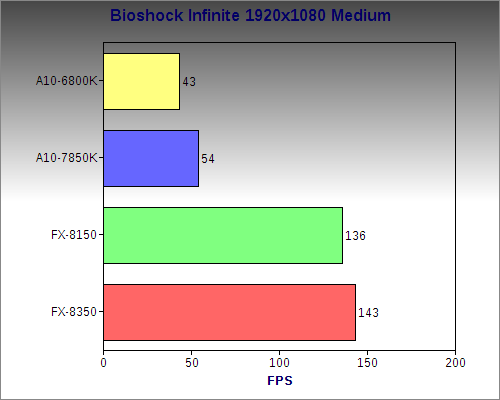
On medium settings, Infinite is surprisingly good and playable, although it did lag a significant amount more when loading a new area. This is a game AMD worked with Irrational to get the AMD Evolved certification for, and it shows that this game was made to play well with GCN. Anyone looking to play Bioshock Infinite on Kaveri will have no problems.
Tomb Raider
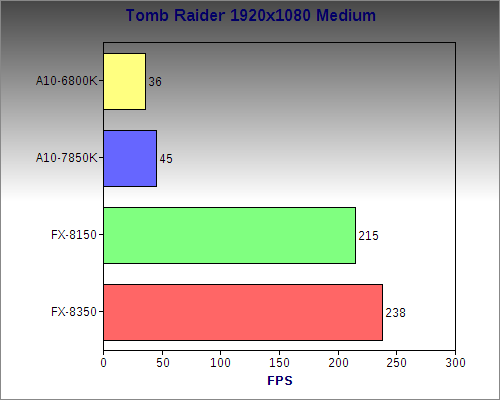
Tomb Raider was also very playable, but as with other games, we can see that it is no match for a high end discrete card.
While I didn’t benchmark it due to there being far too many variables on the server-side to do a reliable test with, I can say I was able to run Team Fortress 2 at 1920x1080 with no problem.
Conclusion:
Kaveri is a bit of a mixed bag at the moment. There are more than a few regressions from Richland at the moment in the CPU department. There were tradeoffs in going to a 28nm process, and one of them was that overall clockspeed reduced, so despite some gains in per-clock performance, there is a net loss in overall CPU performance. AMD also seems to have engineered this to have the greatest performance per watt at lower TDP’s, so the 100W 7850k is at the point of diminishing returns on power consumption increases.
However, the GPU is another story. While GCN has been around since 2011 with the launch of the Radeon 7970, Kaveri and the lower-end Kabini are first time AMD has had it in an APU, with Llano paired with Radeon 5000’s VLIW5 and Richland/Trinity paired with Radeon 6000’s VLIW4. AMD has noted that nearly 50% of Kaveri’s die space is just the GPU, with the remaining 50% being divided between the CPU, interconnects, and cache. For its TDP, I was genuinely shocked at some points at how it stacked up against a full Radeon 7970 with 3GB of its own GDDR5. In the PCMark tests, there was less than a 25% difference in OpenCL accelerated tasks, even with Kaveri’s GPU having much lower bandwidth and being paired with a CPU that had half the modules and no L3 cache. Gaming is very dependent on the particular title, but with Mantle and DirectX12, both AMD and Microsoft are promoting more lower-level coding than was previously possible.
However, Kaveri is in no way an FX replacement. In almost every CPU-bound task, the FX-8350 trounced every other chip by a good margin. If you have an FX-8350 and are looking to upgrade to another AMD build, it appears you’ll be stuck for a while. AMD has no plans on their roadmaps to release a four-module Steamroller chip or a Kaveri without a GPU that can be clocked higher. In fact, AMD’s roadmaps also show no server replacement for existing Piledriver chips. Kaveri’s replacement will be an Excavator based chip called Carizzo, whose TDP will cap out at 65W, and will also be on a 28nm process. It will be interesting to see how Excavator turns out, given it’s the earliest possible chip that Jim Keller could have influenced. Keller is now in charge of AMD’s CPU design, having previously designed the legendary Athlon 64, also known as K8 and Hammer. Keller also worked at PA Semiconductor as well as Apple after PA Semiconductor was acquired, and his influence can be seen on Apple’s chips like the A6 and A7.
AMD has a large fabrication gap between themselves and Intel. While this is at 28nm, Intel has had 22nm chips on the market for two years, and while it appears to have been delayed, 14nm chips will possibly be on the market by the end of the year. As they no longer own their own fabrication plants, AMD is dependent on whatever GlobalFoundries can put out. However, by leveraging their GPU’s and getting developers onboard with new ways of programming with HSA and Mantle, this has the potential to be alleviated somewhat. Keller stated in an interview with Rage3D that “AMD are on track to catch up on high performance cores”, so he is confident that the performance gap will not be around for very long.
In today’s world, however, I can easily recommend Kaveri to potential builders that don’t want a discrete GPU in a build. It’s capable of 1440x900 gaming in most titles and 1920x1080 in some, and game performance should improve with future titles due to the use of Mantle and CPU’s favoring parallelism over individual core strength. I’d also easily recommend it to people wanting a simple machine for browsing the web, office work, some light photo editing, etc, although I would recommend the lower-clocked A8 and not the A10. Kaveri may not be the game changer some thought it would be, but it does a good job of establishing HSA, unified memory, and furthering OpenCL’s use of a GPU for greater performance.
Review Summary
Kaveri is a step forward in AMD's vision of the future, but it exhibits growing pains and is at times a regression from its predecessor. The best has yet to come with what this chip has in store.
(Review Policy)Have a tip, or want to point out something we missed? Leave a Comment or e-mail us at tips@techraptor.net

I've been a lover of video games, writing, and technology for as long as I remember. I have a B.A. in English from the University of Illinois at Urbana… More about John











